

Semantic similarity is often estimated using word2vec, but the freely available algorithms are not good enough [1, 2, 3]. Other word embeddings seem to be more successful [1, 4, 5]. Another (more rigorous) approach – through enriching wordnet with semantic relations from other thesauruses with subsequent clustering [6]. The third approach is to measure Sentimental similarity [7], possibly empowering by various word-emotion associations [8, 9, 10, 11]. Our goal is to find the winning combination of all of these approaches, that could be used for identifying our moods, opinions, values, cause-effect sequences, and automated decision making in Global Wisdom Network. Note that similarity may differ from association (e.g., coffee and cup are not similar, but associated) [12], and we may need both of them
{kind=link}
[1] How can I get a measure of the semantic similarity of words?
[2] Free algorithm(s) for semantic similarity, but the results are disappointing, e.g. prudent + thoughtful (synonyms!) = 0.193, but prudent + careless (antonyms!) = 0.43; eccentric + odd (synonyms!) = 0.35, but eccentric + normal (antonyms!) = 0.275
[3] Another compilation of free algorithms is here
[4] Integrating Distributional Lexical Contrast into Word Embeddings for Antonym-Synonym Distinction
[5] ConceptNet is used to create word embeddings — representations of word meanings as vectors, similar to word2vec, GloVe, or fastText, but better
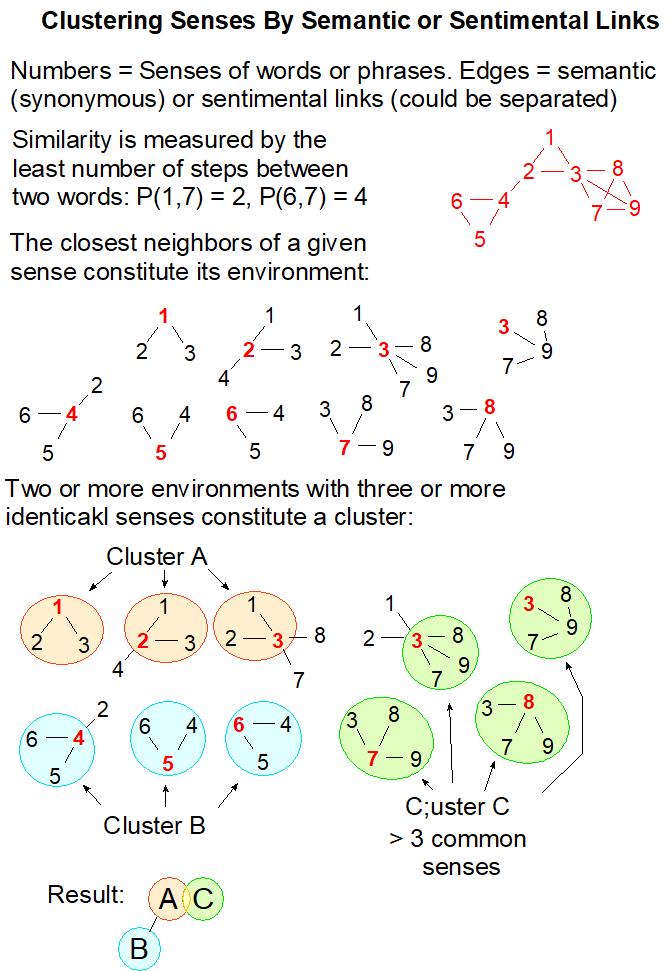
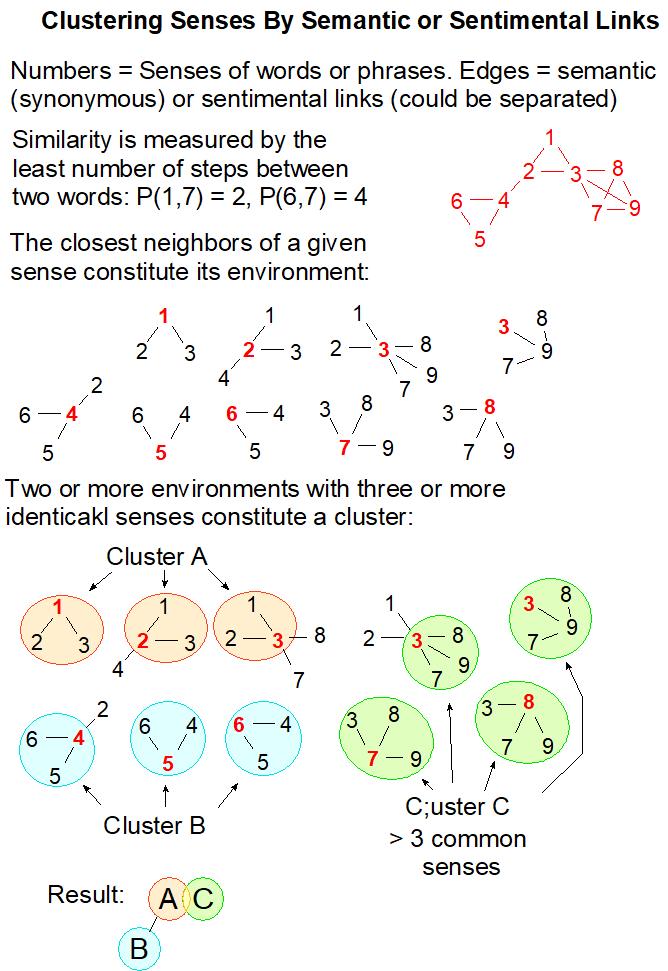
[6] Enriching wordnet with synonyms, near-synonyms, antonyms, near-antonyms from Merriam Webster , Word Hippo , Thesaurus Plus , Thesaurus.com , The Free Dictionary, and other thesauri, with subsequent semantic clustering and counting the chain lengths
[7] Mohtarami et al (2012) Sense Sentiment Similarity
[8] Mohammad, Sentiment and Emotion Lexicons
[9] Mohammad, Valence, Arousal, and Dominance for 20,000 English Words
[11] Sungjoon et al (2019) Toward Dimensional Emotion Detection from Categorical Emotion Annotations
[12] SimLex-999: Evaluating Semantic Models With (Genuine) Similarity Estimation