

Any data could be converted into graph through pairwise sentiment similarities between entities. Two entities are related, if their similarity exceeds a certain threshold
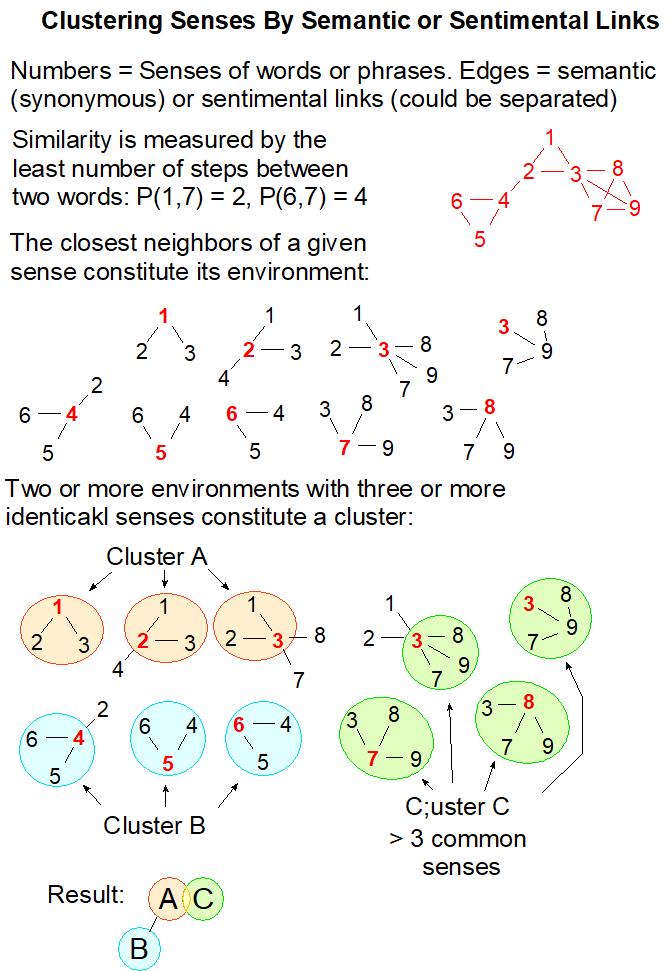
If entities are words, then we will obtain a graph similar to “clustered wordnet”: Sense Sentiment Similarity 2012
If entities are “multi-sensory” (texts, books, music, movies, graphics, persons, companies, events, etc), then we will obtain many different Common Sense Knowledge Graphs, depending on what we want to trace
Each entity can be represented by up to 4 (usually less) layers of senses, using the “psychology of Fourier series“:(i) (nick)names from the finite lists of characters, representing the sharpest psychological impact,(ii) immediate sentiments and emotions of a more general scope,(iii) deeper properties and patterns reflecting permanent traits and functionality,(iv) other facts related to well known phenomena, persons, places, events
Each layer can yield a separate “similarity graph”. There can be 4! = 24 permutations of the “same-level-similarities”, and 10! = 3.6 million of the “cross-level-similarities”. In reality this number should be much lower, as (i) most entities should be described by 2 – 3 layers of senses, and (ii) most “cross-level-similarities” should be redundant
Senses of each similarity layer could be arranged into some hierarchical structure. E.g. all emotions could be split into three overlapping groups, each of which could be split into few sub-groups, etc. All movie characters could be arranged alike (although with higher controversy). All words can be split into hyponymic groups
All hierarchic / sensoric levels could be related to various colors, shapes or musical melodies, so that all multi-sensory entities could represent a “multidimensional symphony” acting like a living organism, for which we could predict various “homeostatic features” using “dialectic wheels” of sentimental and character levels
… all this could start with a “simple” sentimental similarity algorithm — but I doubt that the “large corpus / wordvec” approach will be sufficient … somehow enriching wordnet with other thesauri and word-emotion annotations, with subsequent clustering and “semantic distance counting”, looks more reliable … and the results, after proper visualization and linking to other languages, could be useful for all translators, computational semantics (through API?), perhaps some psychologists, and Atlas users
{kind=link}